Opportunities and challenges for the use of common controls in sequencing studies
Abstract
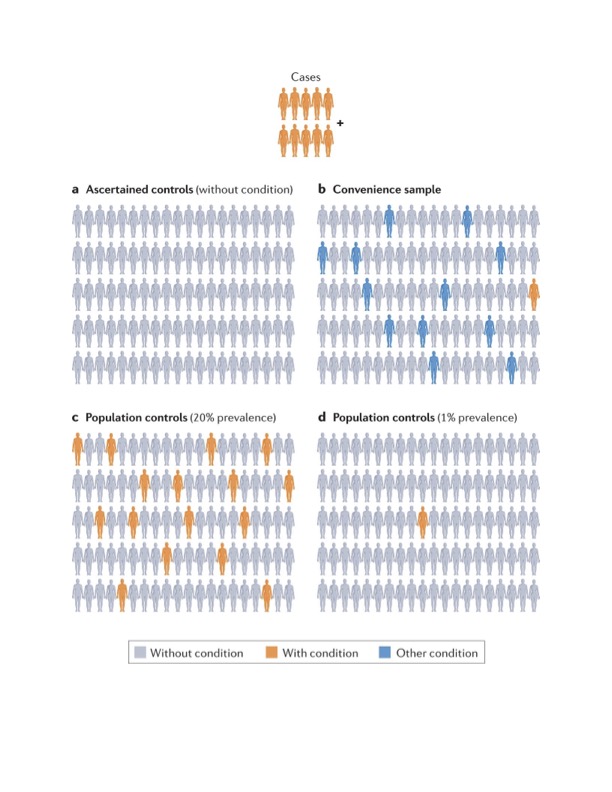
Genome-wide association studies using large-scale genome and exome sequencing data have become increasingly valuable in identifying associations between genetic variants and disease, transforming basic research and translational medicine. However, this progress has not been equally shared across all people and conditions, in part due to limited resources. Leveraging publicly available sequencing data as external common controls, rather than sequencing new controls for every study, can better allocate resources by augmenting control sample sizes or providing controls where none existed. However, common control studies must be carefully planned and executed as even small differences in sample ascertainment and processing can result in substantial bias. Here, we discuss challenges and opportunities for the robust use of common controls in high-throughput sequencing studies, including study design, quality control and statistical approaches. Thoughtful generation and use of large and valuable genetic sequencing data sets will enable investigation of a broader and more representative set of conditions, environments and genetic ancestries than otherwise possible.